Emacs as your code-compass: what is this text about -- without me reading it?
Too long; didn't read
(Structured) text has a lot of noise in it. Data scientist use some simple text analyses to extract meaning from text without reading sequentially. Let's do the same! In this post I am sharing how to extract information from commit messages and functions without a careful read.
The problem
Sometimes I am on a rush and I find myself in front of a block of text that hides its meaning. What is this function doing? That is what I need to know, but there is so much accidental noise that I need to recur a patient reading. So here we go, check the input the return type, then quickly go through those ifs and elses. A few minutes later, maybe with the help of some tests or a REPL I have a less vague idea of how the function work.
A rough idea is all I needed, but it required quite some mental parsing! Can we do this better?
It is a problem indeed
It is interesting how much we work with text. Some avid readers use speed reading to navigate this ocean of information.
When looking at a new repository, I may wonder what my predecessors worked on. And they took care to keep a log of meaningful messages with all of the changes they committed. However, that also is a wall of text for me, particularly if the project had a long life. And unlucky me, the composition of those messages is not as well connected as a story in a book.
From the history of messages I could get some interesting information though: for example, how many bugs they fixed, what features this software provides, and maybe even how much refactoring happened. Can I get that without a long read?
And there is a solution
Data scientists go for the Pareto principle in text analysis: we want to read 20% of the information and still get out 80% of the value (or something along those numbers).
The easiest analysis we can do is counting words. If you take a piece of text and produce a histogram for the frequency of each words, you may be surprised by how much information you can extract from there.
Say I got this function:
procedure TGildedRose.UpdateQuality;
var
I: Integer;
begin
for I := 0 to Items.Count - 1 do
begin
if (Items[I].Name <> 'Aged Brie') and (Items[I].Name <> 'Backstage passes to a TAFKAL80ETC concert') then
begin
if Items[I].Quality > 0 then
begin
if Items[I].Name <> 'Sulfuras, Hand of Ragnaros' then
begin
Items[I].Quality := Items[I].Quality - 1;
end;
end;
end
else
begin
if Items[I].Quality < 50 then
begin
Items[I].Quality := Items[I].Quality + 1;
if Items[I].Name = 'Backstage passes to a TAFKAL80ETC concert' then
begin
if Items[I].SellIn < 11 then
begin
if Items[I].Quality < 50 then
begin
Items[I].Quality := Items[I].Quality + 1;
end;
end;
if Items[I].SellIn < 6 then
begin
if Items[I].Quality < 50 then
begin
Items[I].Quality := Items[I].Quality + 1;
end;
end;
end;
end;
end;
if Items[I].Name <> 'Sulfuras, Hand of Ragnaros' then
begin
Items[I].SellIn := Items[I].SellIn - 1;
end;
if Items[I].SellIn < 0 then
begin
if Items[I].Name <> 'Aged Brie' then
begin
if Items[I].Name <> 'Backstage passes to a TAFKAL80ETC concert' then
begin
if Items[I].Quality > 0 then
begin
if Items[I].Name <> 'Sulfuras, Hand of Ragnaros' then
begin
Items[I].Quality := Items[I].Quality - 1;
end;
end;
end
else
begin
Items[I].Quality := Items[I].Quality - Items[I].Quality;
end;
end
else
begin
if Items[I].Quality < 50 then
begin
Items[I].Quality := Items[I].Quality + 1;
end;
end;
end;
end;
end;
Note I do not know what this is doing and I do not know Delphi, the language it is written in, either.
Now let's produce the word frequency of it:
word,occurences 'items[i]',32 'begin',21 'quality',20 'end;',18 'then',16 'name',8 'sellin',5 'backstage',3 'concert',3 'else',3 'end',3 'hand',3 'passes',3 'ragnaros',3 'sulfuras',3 'tafkal80etc',3 '(items[i]',2 'aged',2 'brie',2 'and',1 'count',1 'for',1 'integer;',1 'items',1 'procedure',1 'quality;',1 'tgildedrose',1 'updatequality;',1 'var',1
Or for the more visual ones:
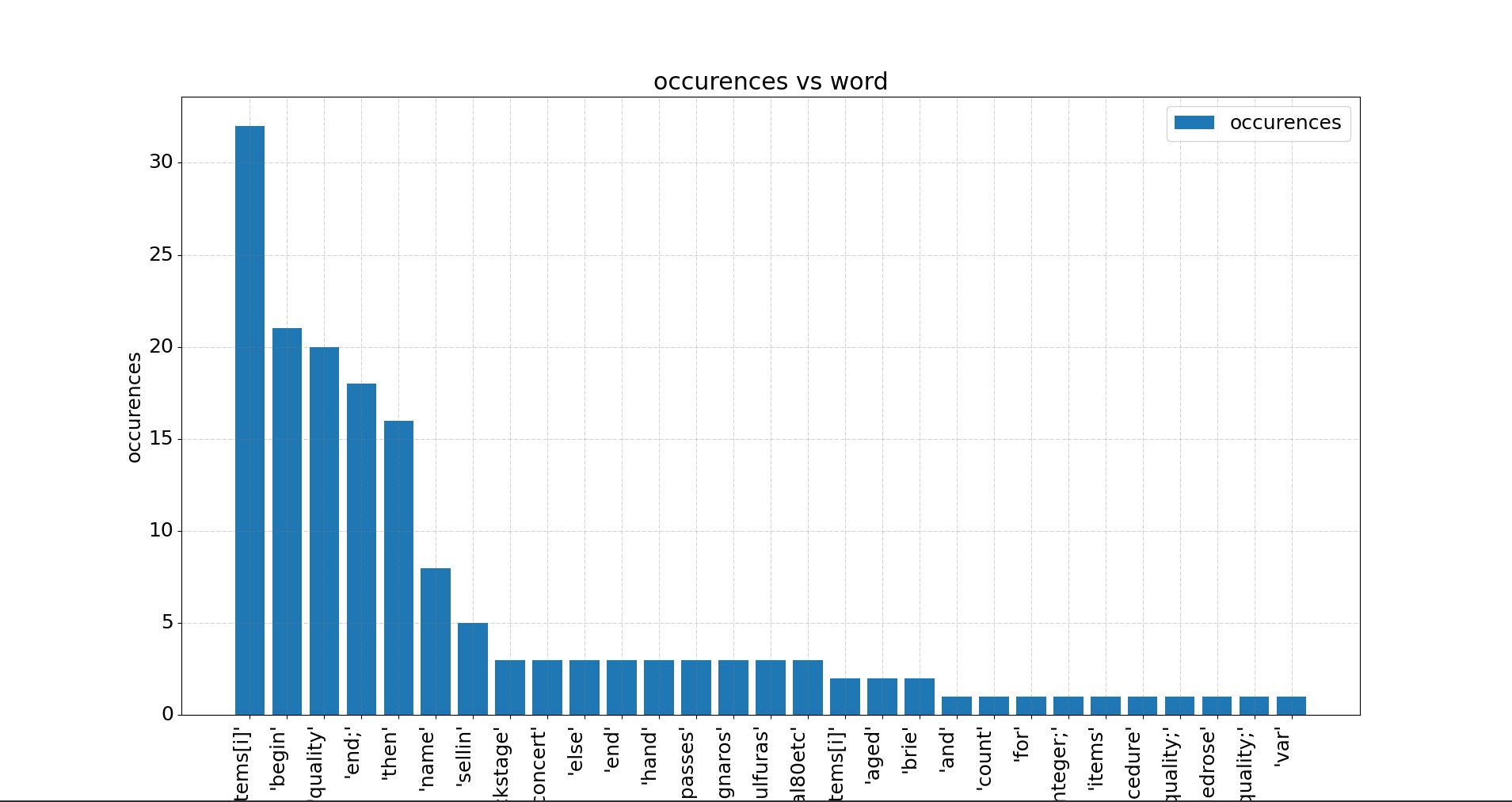
Now you can see a different view of your function:
- it does a lot of iterations (assuming that
items[i]is an iteration in this language), - it has surely something to do with quality because that word appears more than 20 times
- somehow it does something with selling, concert, aged brie and ragnaros(?!)
This surely does not give us a deep understanding (maybe just enough if we have some background context about the file it comes from), but reduces our skimming to just reading the numbers. The picture is even better because it reduces that to read the labels. Indeed, each view is skimming the needed effort and saving us time.
Naturally this is a tool you should use when the trade off seems convenient: in the example I am unfamiliar with the programming language and the function has quite some nesting (complex to read). If it is a one liner and in your favourite language, this analysis will give you a negative result because you still need time to produce it.
You can use the same analysis to skim the messages of a repository. For example, let's look at Selenium messages:
word,occurences
'the',11594
'for',6160
'and',3193
'tests',2505
'simonstewart:',2497
'test',2283
'adding',1779
'that',1774
'fixing',1767
'with',1673
'fix',1668
'from',1560
'firefox',1491
'updating',1422
'add',1420
'not',1319
'driver',1316
'this',1284
'net',1238
'when',1186
'use',1174
'issue',1164
'build',1155
'jaribakken:',1150
'version',1132
'danielwagnerhall:',1077
'code',954
'more',940
'fixes',936
'support',911
'[java]',898
'update',890
'jimevans:',872
'selenium',805
'new',793
'now',785
'java',721
'make',713
...
'yurodivuie:',1
'yuvipanda:',1
'z-order',1
'zaccampbell:',1
'zero-height',1
'zeromq',1
'zerosizeddivisshownifdescendanthassize',1
'zimmerman',1
'zing',1
'zipentry',1
'zipped',1
'zipper_spec',1
'zipping',1
'zips)',1
'zipstorer',1
'zombi',1
'zsh',1
'{a6fd85ed-e919-4a43-a5af-8da18bda539f}',1
'{action',1
'{alert',1
'{assert',1
'{condition',1
'{driver',1
'{enabled',1
'{files',1
'{fulfilled',1
'{iphone',1
'{resource',1
'{safari',1
'{server',1
'{set',1
'{start',1
'{status:0',1
'{win?',1
'|\r\n)/',1
'|this|',1
'~/src',1
'~10x',1
'~40',1
'~>1',1
'¯\_(ツ)_/¯',1
'—allow-cors',1
'‘org',1
'‘remote_connection’',1
'“inc',1
I cut some data because it is... data overdose! Even the picture this time is not as useful because there is simply to much data to handle.
Still from this long history, we can see that:
- "tests" appears a lot of time (it could be a coincidence but Selenium is a tool for testing things)
- "fixing", "issue", "fix" appear more than 4k times
- a lot of commits focused on Firefox
- we also directly see some maintainers names in there
This is not bad from a quick glimpse: we now know that this repository had quite some issues and fixes and we know who are the main maintainers even without a knowledge map.
I have added support to code-compass to analyze text for you. You can use:
c/word-analysis-region-graphto produce the frequency picture for the highlighted regionc/word-analysis-regionfor the above in a textual formatc/word-analysis-commitsfor analyzing the software history of the repositoryif you call this with the universal argument (i.e.,
C-u M-x c/word-analysis-commits) it lets you choose a file and focuses the word analysis only on the commits affecting that file.c/word-semanticswhich shows you the word analysis in reverse orderThe idea is that less used words may carry more meaning than the rest.
c/word-statisticswhich provides the words analysis for the current buffer
Hopefully this saves you some reading time!
Conclusion
So skim the reading when things get difficult for you to parse and let your computer provide the information! Just get code-compass and run its brand new functions!
P.S.
By the way, this was the last scheduled article in my release list! Whoa it was a nice ride. I have still a bunch of features that I am going to release at a slower pace (for example hotspots against your microservice architecture) and I will release articles along with that.
The aim is to reduce the release rhythm so I can experiment and write about other topics that interest me. So code-compass will get better and better over time.
Please get in touch with ideas, requests or suggestions whenever you feel like!
Happy navigating!