Emacs as your code-compass: how fragmented is the knowledge of this file?
Too long; didn't read
Have you ever wondered how fragmented is the knowledge about a file?
Your repository history can tell you that: just use code-compass's
show-fragmentation!
The problem
The more heads at a meeting the more difficult is to take a decision. How does this translate to software? In successful projects multiple authors work together on enhancing software over time. We saw already that multiple changes increase the likelihood of errors. So what happens when people have collaborated over a long time? And when we find a file that has been modified by dozens of authors should we worry?
It is a problem indeed
Say we realize a file has got many authors, and we already know who is the primary author from our knowledge map: what do we know about the familiarity of other authors with the code at hand? How much do they know? What if the main author is actually just about as knowledgeable as anyone else? Would it not be amazing to see these details in a nice visualization? Once this becomes visible, we can assess if the knowledge fragmentation of this file is a problem or not.
And there is a solution
You can visualize knowledge fragmentation because this information is in your repository history (or at least a proxy: you are always the best at assessing this by chatting with the protagonists). The quickest way to extract this information (if you are a terminal savvy) is running the following command in your repository:
git shortlog HEAD -n -s -- code-compass.el
| 11 | ag91 |
| 8 | Blank Spruce |
This shows how many commits the authors have contributed to the given
file (in this case code-compass itself). This can look rather
different for a bigger codebase:
git shortlog HEAD -n -s -- RemoteWebDriver.java
64 Alexei Barantsev 60 Simon Stewart 17 Eran Messeri 10 Daniel Wagner-Hall 10 Luke Inman-Semerau 8 Dounia Berrada 7 Ahmed Ashour 5 Kristian Rosenvold 4 Jason Leyba 3 Kevin Menard 3 Valery Yatsynovich 2 Gerry Gao 2 Jason Juang 2 Joshua Bruning 2 Nina Satragno 1 Alberto Scotto 1 Amit Bhoraniya 1 Chirag Jayswal 1 Dominik Dary 1 Edirin Atumah 1 Erik Kuefler 1 Glib Briia 1 Jari Bakken 1 Jim Evans 1 Jonah Stiennon 1 Paul Hammant 1 Rajendra kadam 1 Vijendarn Selvarajah 1 richard.hines
This is the result for a file in Selenium, a project much older and known than code-compass.
The example in Selenium shows you that there are two maintainers that likely know as much as each other. Still thick threads of knowledge are spread among other contributors. This file happens also to be a hotspot in the Selenium code base, so there is a chance that fragmentation of knowledge may be hiding both errors and design decay.
I like to use a slightly more visual approach to fragmentation though. Also I think that knowledge is more about the lines of code you add and delete from a file than the times you commit. So I use code-maat to look for the authors contribution to a file and calculate the sum of the additions and deletions they contributed to the code. Using commits or lines of code should not yield significantly different results, but I prefer the latter.
The visualization comes in two formats, according to your preference.
For example if you call c/show-fragmentation on code-compass.el,
you can produce the following pictures:
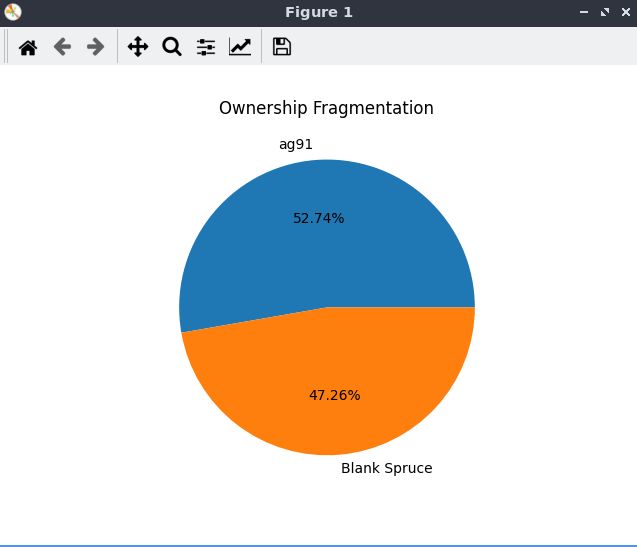
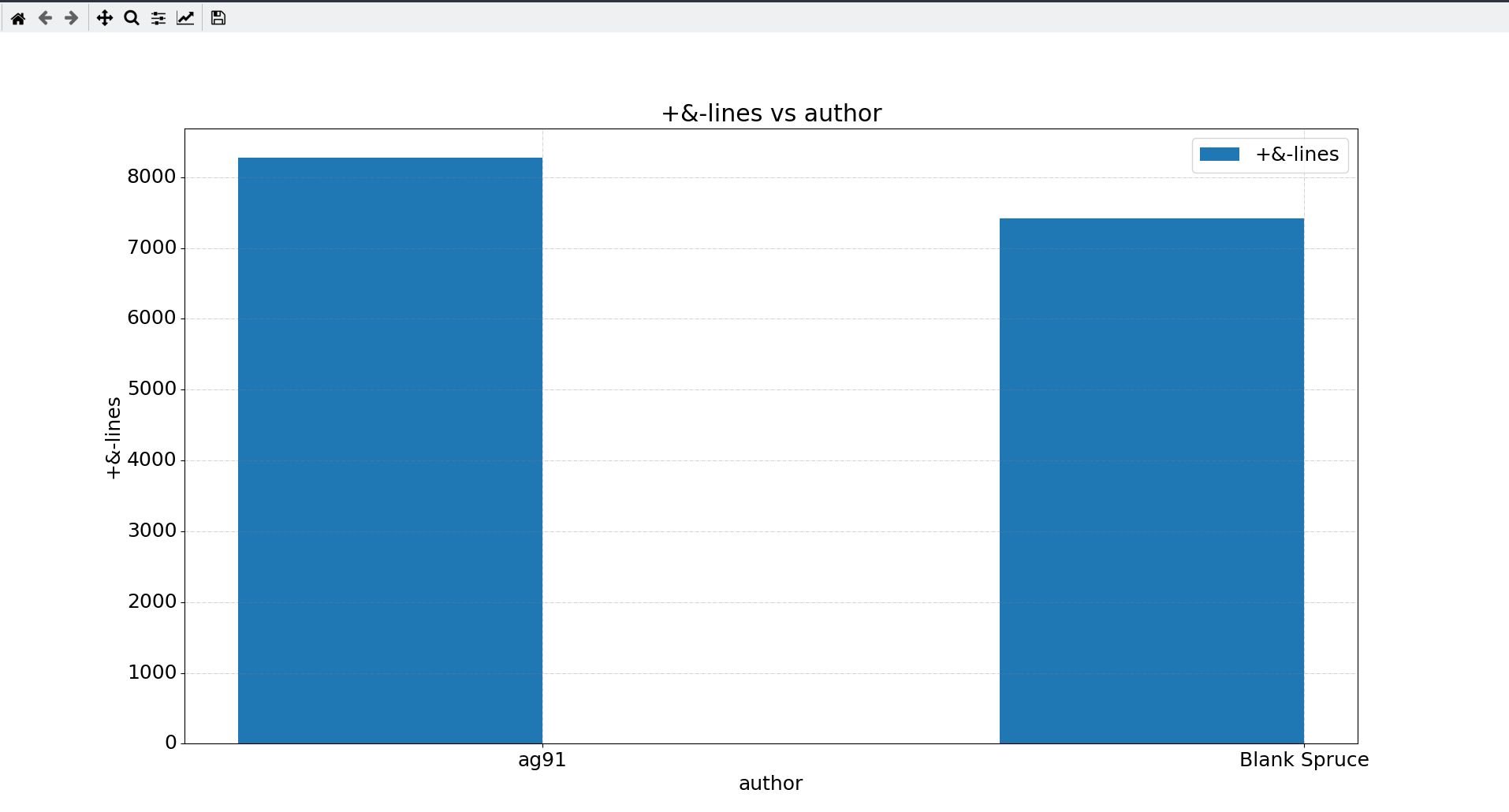
If you prefer the bar chart over the pie chart, you have to just customize c/pie-or-bar-chart-command like the following:
(setq c/pie-or-bar-chart-command "graph %s --bar --width 0.4 --offset='-0.2,0.2'")
Where the --width and --offset options are at your own discretion,
I just proposed what works for me.
If we return to our wild example RemoteWebDriver.java, things look
like this:
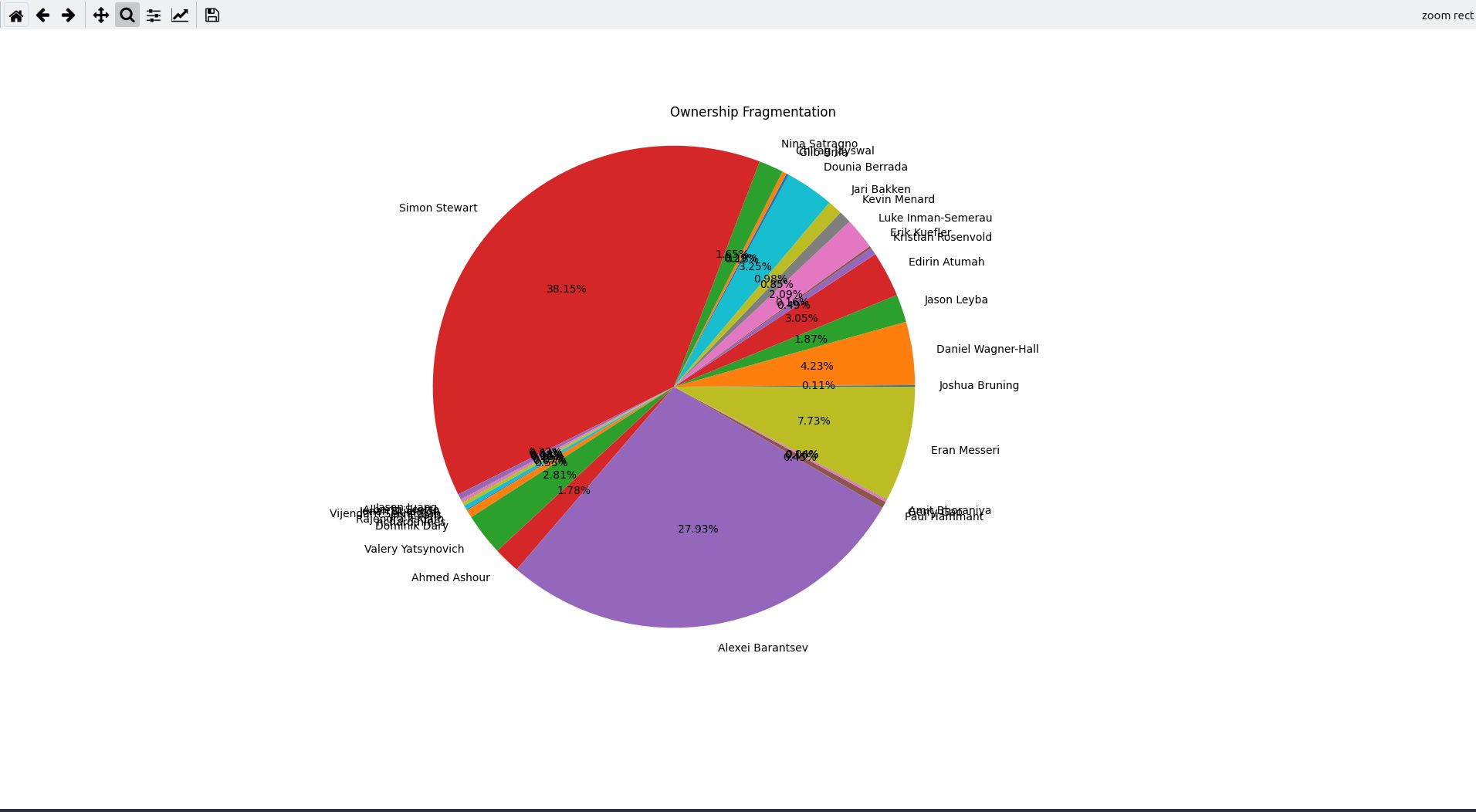
From the lines of code analysis you can see that there is a slightly
more significant division in knowledge between the two main
contributors of RemoteWebDriver.java. If you would like to see
clearly the percentages overlapping, just use the "lens" icon on the
top-left toolbar and make a rectangular region with your mouse: it will
zoom in to see the small percentages more clearly (you can go back
with the arrow icons in the same toolbar).
Now you can visualize knowledge fragmentation: what next? Fragmentation, as an hotspot, has a simple solution: rewrite the file. If the design decayed over time, you have just to understand what was the aim of the software. Then you can rewrite a more synthetic and coherent software to substitute it. Ideally, you can divide the file in multiple smaller parts which are easier to reason about and require less or no further modification. This also reminds me why the Unix people said "worse is better": have small units of software that you can compose to provide what you need. They are easier to understand, require less modifications and you can leverage for more use cases.
Well, now another tool for fragmentation discovery is in your hands!
Conclusion
This is the time: do you have a file that is difficult to understand?
Check if it has tons of authors and how much they know about it with
code-compass c/show-fragmentation (or the plain Git command I showed
above). Then, if that file is really a pain, socialize with them and
try to write a better version of it!
Happy condensation!