Emacs as your code-compass: how complex is this code?
Too long; didn't read
Find out how complex is your (indented) code by using code-compass'
c/calculate-complexity-current-buffer. The best way to interpret
that score is to integrate the time dimension: use
c/show-complexity-over-commits to see how complex your code became
over the last commits.
The problem
Often I am so absorbed by the problem at hand that when my code gets to the review stage, I find comments like: "Mmm, can you make it more readable?". I know I should not rush to the review, but it happens that I have some other work in progress that distracts me. That makes me forget to "empathically" review my code before clicking the "open pull request" button.
(Meanwhile I master sequential problem solving) If only I had a way to quantify code complexity, maybe I could make my preferred editor to stop me at the right time?
It is a problem indeed
Code that is hard to read is a serious issue. Give it enough time and I cannot tell the meaning of my own code! Indeed, time erases from my memory why I structured code in a certain way and why I chose those random names for variables and functions (and luckily so, because otherwise I would not have mental space for my future!).
This is troublesome for my code, and extremely so for organizations because of the quantity of engineers involved (with different backgrounds) and their turnover. This feed the cycle of architectural decay and technical debt.
We already saw we can find this out with the hotspot analysis, and we shall do better: we need a way to quantify how worse or how better we are making code for future maintainers!
And there is a solution
There are a bunch of ways to calculate a complexity score, one of the many being cyclomatic complexity. The simplest, roughest and also language agnostic is code indentation.
Given your code follows a uniform indentation scheme (Emacs has a tons of amazing packages for that), you can easily see if a piece of code is difficult to read. For example, check out the following pieces of code to get the idea (they are meaningless, so ignore the semantics):
(defun someCommonLispFunction (someInput)
(if (> someImput 0)
(if (> someImput 1)
(if (> someImput 3)
"bigger than 3"
(if (= someImput 3)
"equal to 3"
"..."))
"...")))
(let ((someInput 1))
(let ((someOtherInput 2))
(+
(if someInput
1
2)
(when someOtherInput
3))))
(setf a 1) (setf b 1) (+ a b)
I made these up randomly with the only aim to show you how difficult to read is code with too much (unnecessary) nesting.
If you want to see other examples in your favourite programming language, check out https://github.com/emilybache/GildedRose-Refactoring-Kata, which is also a useful refactoring kata.
The point is that your computer can calculate a complexity score easily: just sum up the units of indentation appearing in the code.
The unit of indentation for the Common Lisp code above is two spaces. So the calculation of complexity for each block results in:
| block | complexity |
|---|---|
| block with if statements | 46 |
| block with let statements | 20.5 |
| block with setf | 0.0 |
In my experience I agree with that score when I am reviewing, and researchers found indentation to be a good rough metric to indicate complexity.
Clearly I use this metric as an indication. So rather than looking at the raw number, I look for deltas: I want to see how much my change increases and decreases this complexity value.
This is why code-compass implements c/show-complexity-over-commits,
which lets you see how complexity of a buffer has increased or
decreased over the last few commits. The graph you obtain looks like
this:
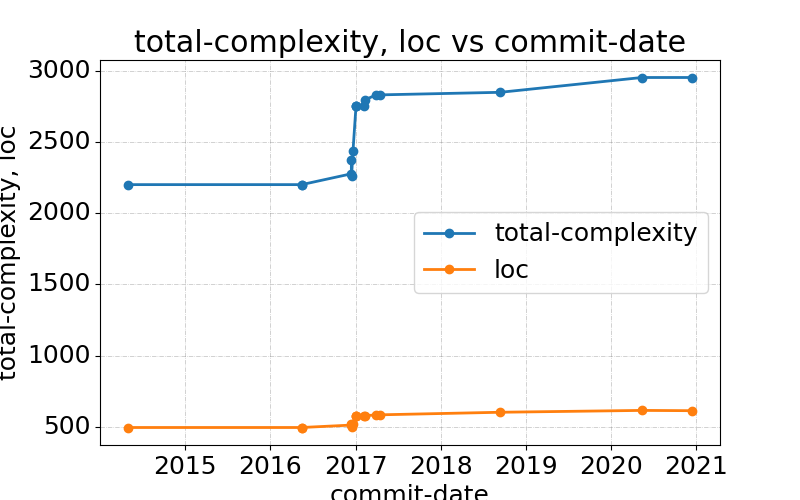
Note that I put complexity in relation to lines of code so that I notice if a spike in complexity is due to a lot of new code added to the file (and this is typical indeed).
Now equipped with this graph, I can find a bit more easily when my changes are a bit too complex to open a pull request :)
Conclusion
So grab the last version of code-compass and find out how complex is
your code by running c/calculate-complexity-current-buffer on a
buffer! Or checking the differential in complexity a file experienced
with c/show-complexity-over-commits.
This way you can evaluate the time future maintainers will have to invest in understanding your code, and save that for them.
Happy simplifying!