Moldable Emacs: how to get useful info about a buffer without reading it
Too long; didn't read
You can get useful information about a buffer without reading it. Here I show moldable-emacs's Stats mold which can help you find some of the salient bits of your buffer.
The problem
I have spent some time reviewing code. Often I could avoid to read it to find out things I could improve. For example, I know code is getting too complex if there are too many if-else around. That need pushed me to build code-compass. In moldable-emacs I want to work in terms of buffers though. I want a gist of a buffer. The gist should change according to the context I am dealing with. That is, if I am looking at text show me number of words and reading time, but if I am looking at code show me how many if-else I got.
How would such a mold look like?
And there is a solution
The mold I came up with is "Stats". Let me give you a sense of how it looks.
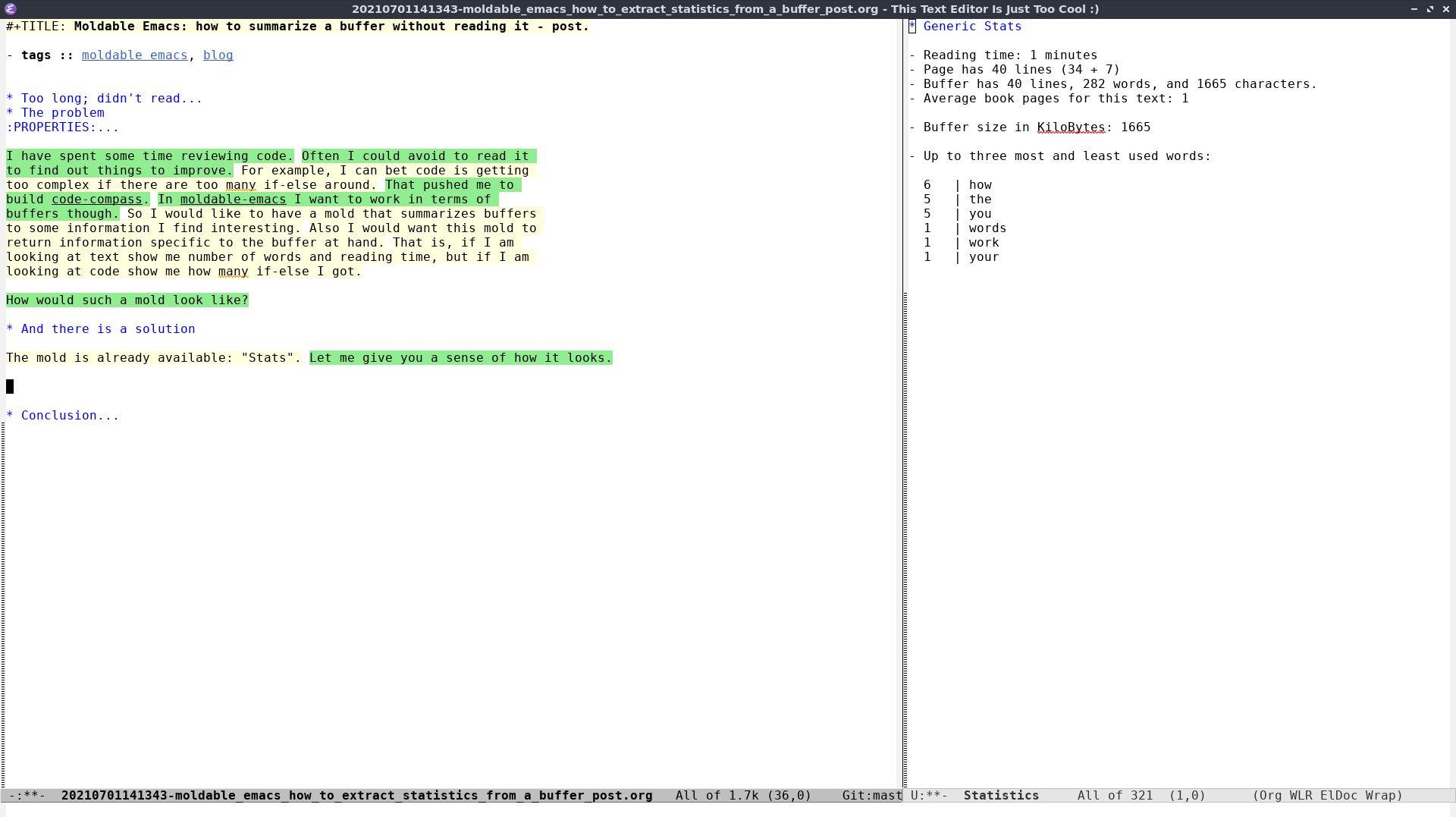
For an Org buffer we get some generic stats. Things like reading time, number of lines, size and most and least used words. Reading time and book pages for example help me to keep things manageable for the reader.
The very same mold works differently for a piece of code, though! Let's take a GildedRose file as an example.
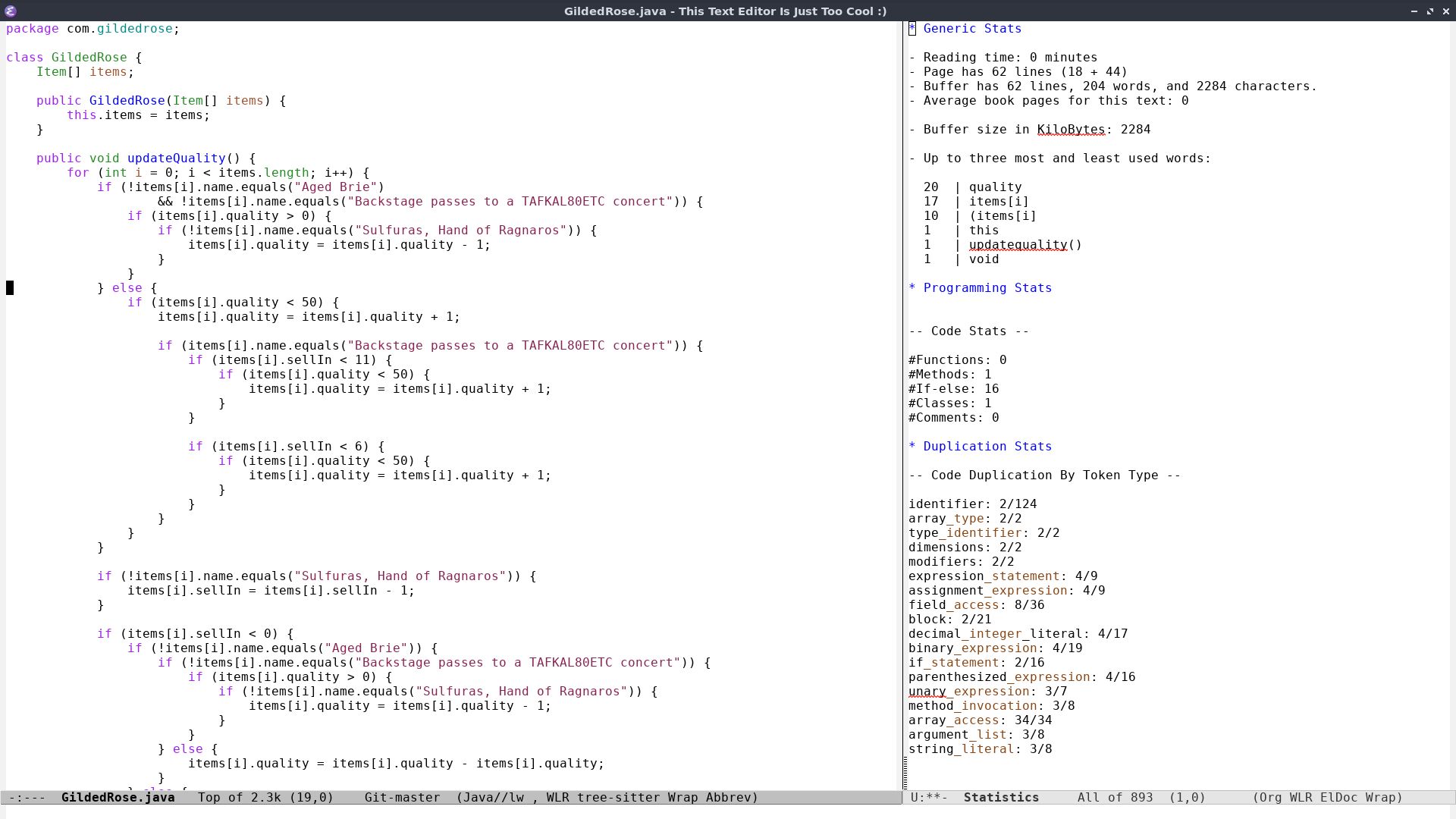
Now in the result of the mold, we have some Programming Stats! We can
see that this code has 62 lines but also 16 if-else. You can see that
the mold detects the method and the class. Under the hood this is
using the amazing emacs-tree-sitter. We parse the code and label
tokens according to the available Java grammar. I tested this mold
with Scala, Java and Python for now. Grammars use slightly different
names for things: for example the Scala grammar uses
class_definition while the Java grammar uses class_declaration.
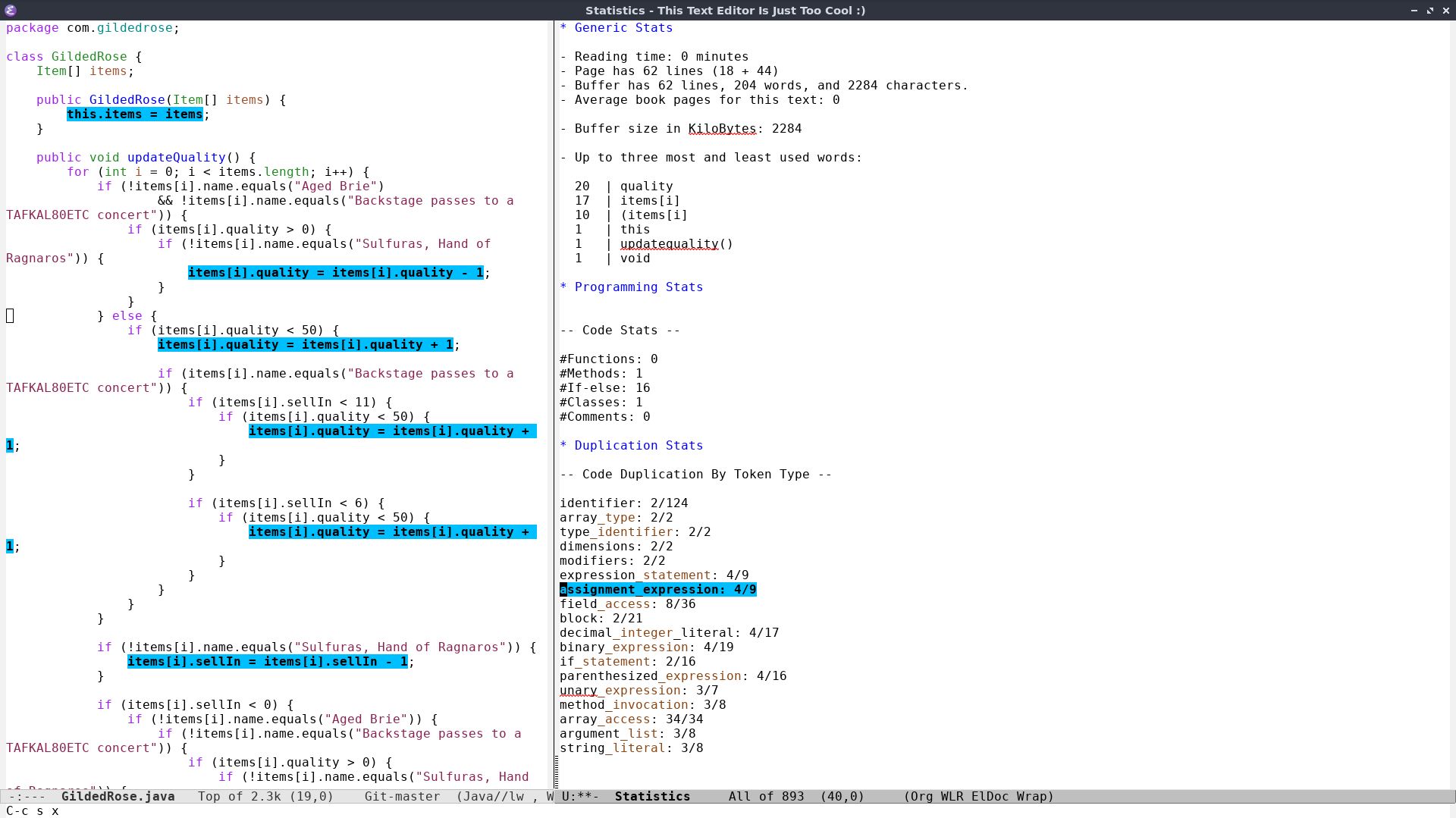
Anyway, let me show you a cool side of this mold!
(you can check a video here: https://user-images.githubusercontent.com/6580039/129642956-eb1fb07e-8fee-42b1-b688-37c64af8b132.mp4)
At the bottom we have some duplication stats. The idea is to make
redundant text evident. For code we want to see redundant constructs.
nSo the highlighted assignment_expression indicates that 4 out of 9
variable assignments are redundant. When your pointer passes over one
of the lines, you see all the tokens matching the type. This is good
enough to find duplication in this example. An improvement over this
would be to highlight only the duplicates. When I firstly wrote this
mold, I was getting just the text, but I had no idea what an
assignment_expression meant! Luckily emacs-tree-sitter comes with
a query language to highlight tokens you care about. In a future post
I shall explain how I made this highlighting system! (I plan to make a
programming language explainer: think of "I don't know that
construct", call a mold and it tells you what it does.)
For now this highlighting uses tree-sitter and so duplication stats
work only for code. I would like to extend that to any other text as
soon I find a good way to structure natural language (machine learning
I guess?).
Conclusion
That was it! Give a try at extracting stats from your buffer with moldable-emacs. And get in touch if you have ideas on how to improve this mold.
Happy stats!